一、JUnit单元测试
单元测试又称模块测试,属于白盒测试,是开发者编写的一小段代码,用于检验被测代码的一个很小的、很明确的功能是否正确。通常而言,一个单元测试是用于判断某个特定条件(或者场景)下某个特定函数的行为。
1.什么是JUnit
JUnit是用于编写可复用测试集的简单框架,是xUnit的一个子集。xUnit是一套基于测试驱动开发的测试框架,有PythonUnit、CppUnit、JUnit等。
JUnit测试是程序员测试,即所谓白盒测试,因为程序员知道被测试的软件如何(How)完成功能和完成什么样(What)的功能。
多数Java的开发环境都已经集成了JUnit作为单元测试的工具,比如IDEA,Eclipse等等。
2.JUnit优点
另外JUnit是在极限编程和重构(refactor)中被极力推荐使用的工具,因为在实现自动单元测试的情况下可以大大的提高开发的效率,但是实际上编写测试代码也是需要耗费很多的时间和精力的,那么使用这个东西好处到底在哪里呢?
极限编程:
要求在编写代码之前先写测试,这样可以强制你在写代码之前好好的思考代码(方法)的功能和逻辑,否则编写的代码很不稳定,那么你需要同时维护测试代码和实际代码,这个工作量就会大大增加。因此在极限编程中,基本过程是这样的:构思-> 编写测试代码-> 编写代码-> 测试,而且编写测试和编写代码都是增量式的,写一点测一点,在编写以后的代码中如果发现问题可以较快的追踪到问题的原因,减小回归错误的纠错难度。
重构:
其好处和极限编程中是类似的,因为重构也是要求改一点测一点,减少回归错误造成的时间消耗。
其他情况:
我们在开发的时候使用JUnit写一些适当的测试也是有必要的,因为一般我们也是需要编写测试的代码的,可能原来不是使用的JUnit,如果使用JUnit,而且针对接口(方法)编写测试代码会减少以后的维护工作,例如以后对方法内部的修改(这个就是相当于重构的工作了)。另外就是因为JUnit有断言功能,如果测试结果不通过会告诉我们哪个测试不通过,为什么,而如果是像以前的一般做法是写一些测试代码看其输出结果,然后再由自己来判断结果是否正确,使用JUnit的好处就是这个结果是否正确的判断是它来完成的,我们只需要看看它告诉我们结果是否正确就可以了,在一般情况下会大大提高效率。
3.为什么要用JUnit
测试框架可以帮助我们对编写的程序进行有目的地测试,帮助我们最大限度地避免代码中的bug,以保证系统的正确性和稳定性。
很多人对自己写的代码,测试时就简单写main,然后sysout输出控制台观察结果。这样非常枯燥繁琐,不规范。缺点:测试方法不能一起运行,测试结果要程序猿自己观察才可以判断程序逻辑是否正确。JUnit的断言机制,可以直接将我们的预期结果和程序运行的结果进行一个比对,确保对结果的可预知性。
4.断言概述
编写代码时,我们总是会做出一些假设,断言就是用于在代码中捕捉这些假设。
可以将断言看作是异常处理的一种高级形式。
断言表示为一些布尔表达式,程序员相信在程序中的某个特定点该表达式值为真。注:以上内容转自CSDN,原文链接:https://blog.csdn.net/qq_42146402/article/details/127590932
二、JUnit技术学习
首先我们需要添加依赖
<!-- https://mvnrepository.com/artifact/org.junit.jupiter/junit-jupiter-api -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.9.1</version>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-params</artifactId>
<version>5.9.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.junit.jupiter/junit-jupiter-params -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-params</artifactId>
<version>5.9.1</version>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-suite</artifactId>
<version>1.9.1</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.junit.platform/junit-platform-suite -->
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-suite</artifactId>
<version>1.9.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.junit.jupiter/junit-jupiter-engine -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.9.1</version>
<scope>test</scope>
</dependency>对于依赖这里并不多做解释
1.常用注解
@Test
通过"@Test"注解表示当前方法是一个测试用例
@Test
void test1() {
WebDriver webDriver = new ChromeDriver();
webDriver.get("https://www.baidu.com/");
}当我们运行执行这个方法以后

可以看见左下角测试用例已经完成并在控制台上有测试用例数量和测试用例通过数量
这样我们就可以避免通过写一个method()方法,再通过调用该方法去实现测试了
注意:测试用例返回值一定是一个void
@BeforeAll
该注解表示在当前类中所有测试用例执行之前执行这个方法
@AfterAll
该注解表示在当前类中所有测试用例执行之后执行这个方法
@BeforeEach
该注解表示在当前类的每一个测试用例执行之前执行这个方法
@AfterEach
该注解表示在当前类的每一个测试用例执行之后执行这个方法
@Disabled
该注解表示忽略当前测试用例,即当前测试用例无需执行
2.测试用例执行顺序
通过在类前添加@TestMethodOrder(MethodOrderer.OrderAnnotation.class)注解然后在对应方法中以@Order(int value)注解来决定测试用例执行顺序
注意:Order注解中value的值通过大小来决定权重,简而言之,当这个数值越大,测试用例执行顺序越靠后
当然测试用例也可以随机不指定执行顺序,采用@TestMethodOrder(MethodOrderer.Random.class)注解就可以实现该效果
3.参数化
首先,可以肯定或者需要说明的是,通过JUnit去写测试用例方法的时候,我们不能像写程序代码一样去写一个method然后传入一个或者多个参数,如method(int x, int y)这样写出来的测试用例会抛出一个参数未注册的异常,但是很多测试用例又需要数据去驱动执行,比如登录功能最起码也要有账号密码,所以我们就需要参数化了
1)单参数
这里单参数是指传进去的参数类型是单个类型
如何实现这样的操作呢,我们需要使用@ParameterizedTest注解表明我们需要参数化(更准确的说是该注解表明我们进行了参数注册),然后通过@ValueSource注解放入想放入的数据类型,之后再按照方法的正常写法去传入参数就好,如下所示
@ParameterizedTest
@ValueSource(strings = {"1","2","3"})
void test2(String s){
System.out.println(s);
}
通过执行结果我们可以看到,这个测试用例执行了三次,或者是这么一个测试方法,由于传了三次参数,所以是三个测试
注意:@ParameterizedTest注解不能与@Test注解一起使用
2)多参数
当我们需要传入多个,或者多组参数时,单参数明显不能满足我们的需求,于是我们便有了多参数传入
csv
代码示例
@ParameterizedTest
@CsvSource({"1,2", "3,4"})
void test3(String s, int num) {
System.out.println(s + " " + num);
}
通过代码示例以及截图我们可以看到,第一组数据为字符类型1与整型类型2一起输出,第二组为3和4
但是当我们的测试用例需要执行很多组数据测试时,仅仅通过以上方法去人为输入参数就不太现实了于是我们就有了csv文件的参数化
@ParameterizedTest
@CsvFileSource(resources = "test1.csv")
void test4(int id, String name) {
System.out.println("id = " + id + "name = " + name);
}通过以上代码我们读取了一个名为test1的.csv文件,当然这个文件是自己创建的,具体创建过程这里不做讲解,之后我们就会看到测试用例被执行了

方法
在我们执行测试用例的时候,可能会出现参数需要被处理,或者是需要某个被一些方法处理过的结果来当做参数传入
@ParameterizedTest
@MethodSource("generator")
void test5(String num, String name) {
System.out.println(num + " " + name);
}这是我们的测试用例,通过@MethodSource("generator")注解表示需要进行参数化的方法,方法名为"generator"
public static Stream<Arguments> generator() {
return Stream.of(Arguments.arguments("1,小张", "2,小李"));
}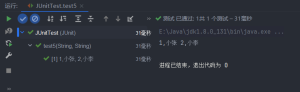
如图我们就完成了这样一个参数的传入以及测试用例的执行
4.断言
在Java中我们通过if语句判断我们需要的条件,在JUnit中我们则通过断言来确定我们的测试用例结果预期
断言相等
断言不相等
断言为空
断言不为空
@ParameterizedTest
@ValueSource(strings = {"1"})
void test6(String num){
//断言相等
Assertions.assertEquals(num,"1");
//断言不相等
Assertions.assertNotEquals(num,"1");
//断言为空
Assertions.assertNull(num);
//断言不为空
Assertions.assertNotNull(num);
}5.测试套件
当我们需要执行很多测试用例或者测试文件的时候,我们就需要用到测试套件
@Suite
@SelectClasses({JUnitTest.class, JUnitTest1.class})
public class RunSuite {
}通过上述注解,我们就可以通过这个类去执行我们想要的测试用例了,当然这只是通过类去执行,我们还可以通过包名去执行测试用例只需要在@Suite注解下使用相对应的注解再表明需要执行的包/类就可以了


✌
O(∩_∩)O哈哈~